前言
在往期文章 一个另类的RVC实现方式 – Arasaka ltd. 中,我简单介绍了RVC变声器,在此感谢开发团队的辛勤工作和社区的帮助,让该项目越来越好
该项目的一些特点
- 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
- 即便在相对较差的显卡上也能快速训练
- 使用少量数据进行训练也能得到较好结果(推荐至少收集10分钟低底噪语音数据)
- 可以通过模型融合来改变音色(借助ckpt处理选项卡中的ckpt-merge)
- 简单易用的网页界面
- 可调用UVR5模型来快速分离人声和伴奏
- 使用最先进的人声音高提取算法InterSpeech2023-RMVPE根绝哑音问题。效果最好(显著地)但比crepe_full更快、资源占用更小
- A卡I卡加速支持
准备:开始
首先,你需要明白你需要训练什么音色,这个音色是要真实存在的,可以是某款游戏或者动漫、电影里的某一个人物,并且可以保证能够收集到至少5-10分钟甚至更多的数据,而不是空想出来,反之,你应该关闭这个页面并在Google上寻找一个合适的音频处理软件对你或者你想变声的声音进行调整
训练一个RVC模型非常的简单,大概步骤是:
- 收集数据
- 处理数据
- 数据切分
- 提取音高
- 开始训练
- 构建索引
- 完成
那么,接下来让我们真正开始训练
开始
让我们开始收集数据,你可以通过一些工具来解包游戏获得声音,也可以通过下载工具下载视频,音乐,电影….
在这里,我不会详细介绍如何解包某款游戏或者下载某平台的视频音乐等等,请你自己解决
然后,通过The Ultimate Vocal Remover Application提取干声
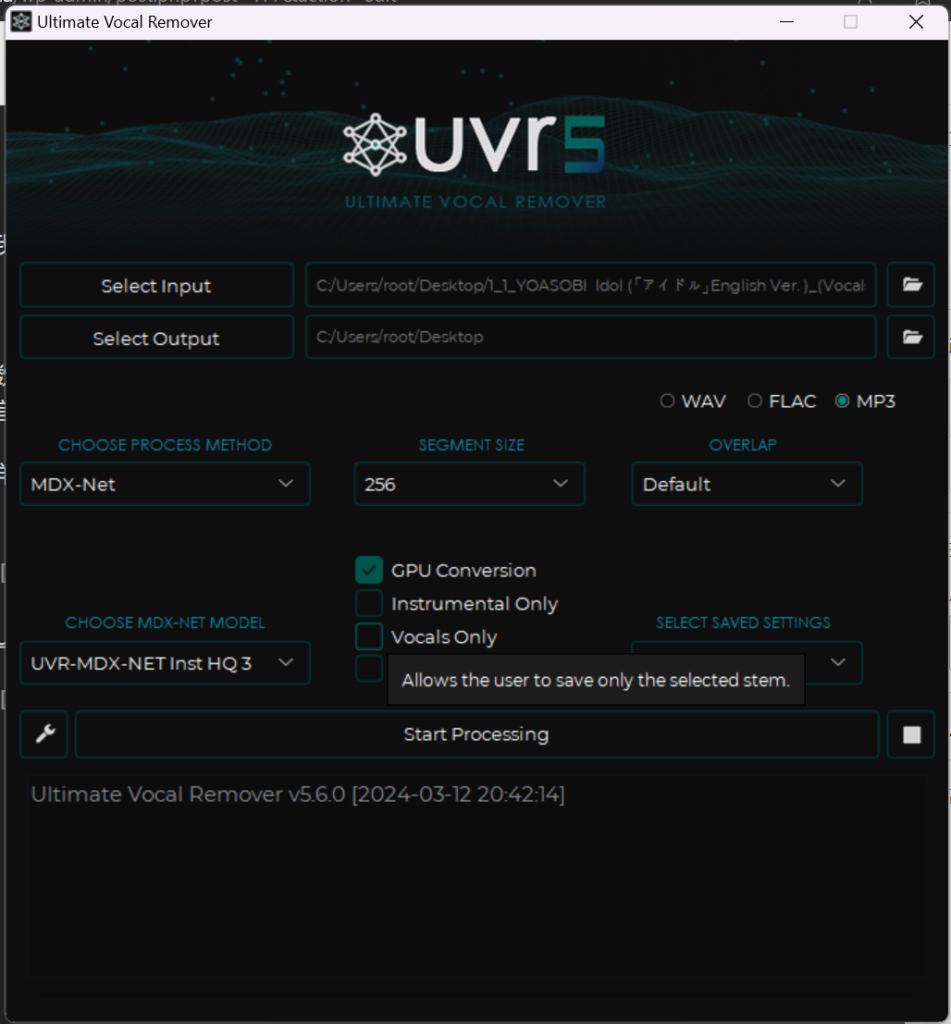
我不会在这里详细介绍如何使用UVR5的使用方法,但我会为你推荐几款模型
首先,使用UVR-MDX-NET inst HQ3 将人声分离出来,你只需要vocals,所以勾选Vocals Only
然后,使用VR模型中的UVR-DeNoise使人声更加纯净(如果你需要训练的声音有一定特点比如:机器人,请不要使用它)
随后,使用UVR-DeEcho-DeReverb去除一些和声和混响与延迟(如果你需要训练有特点的声音比如:庞然大物,请不要使用它)
最后(可选)如果你的声音数据中有多个人,请使用 5或6_HP-Karaoke-UVR提取主人声
然后,重命名你的声音数据使其井然有序,比如
- lala (1).wav
- lala (2).wav
- lala (3).wav
- ……
将他们放到一个文件夹内,不要有空格,启动RVC Webui(go-web.bat)
如果你没有nvidia gpu或者不想在本地训练,可以跟随RVC官方推荐的 AutoDL·RVC训练教程 · RVC-Project/Retrieval-based-Voice-Conversion-WebUI Wiki · GitHub
启动后,程序会自动打开浏览器并打开一个页面
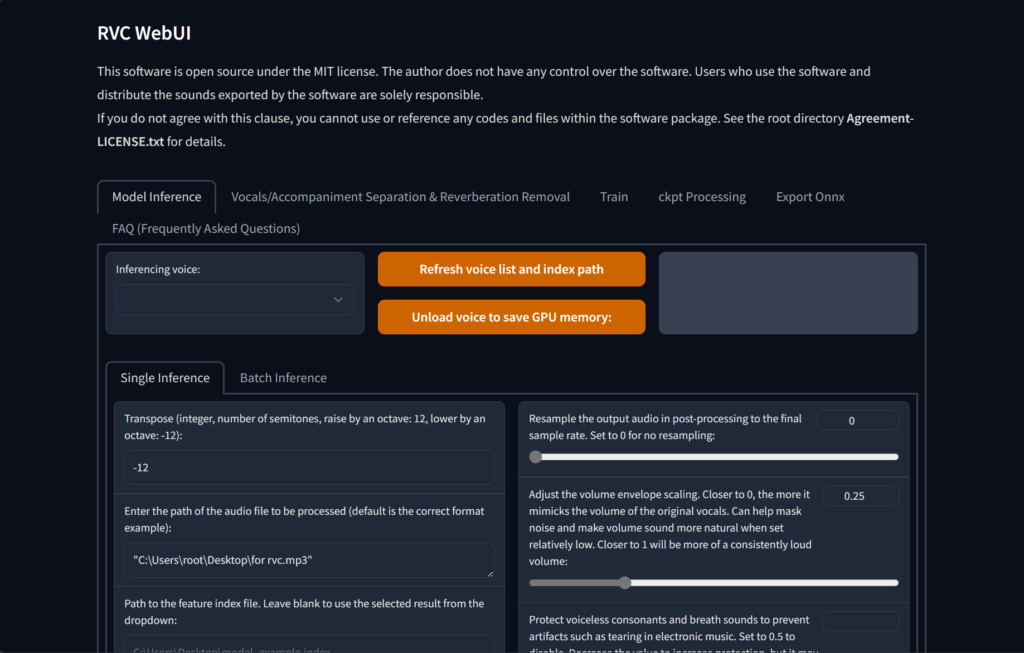
点击 训练
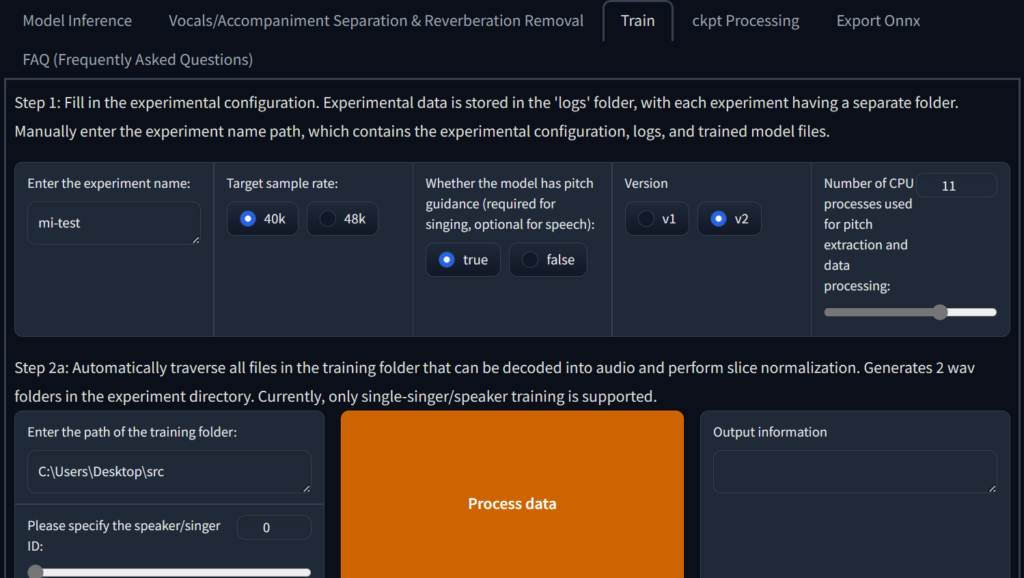
在 输入实验名 那里输入一个名字,不要有空格,建议使用拼音或者英文,可以是你训练的人物名字
目标采样率选择40k就够了,如果你的声音数据有48k当然训练48k更好
音高指导我建议勾选 是 无论你是否使用该模型唱歌,因为人平时说话是多变的
CPU进程数建议保持默认,如果你对你的硬件有信心可以调高或拉满
然后对着你的训练数据文件夹 Shift + 右键 复制为路径
然后粘贴到 输入训练文件夹路径 别的 千万别动
然后选择处理音高的模型,我建议使用 rmvpe_gpu 如果你有多张显卡可以按照说明进行更改
然后下滑到最后一栏
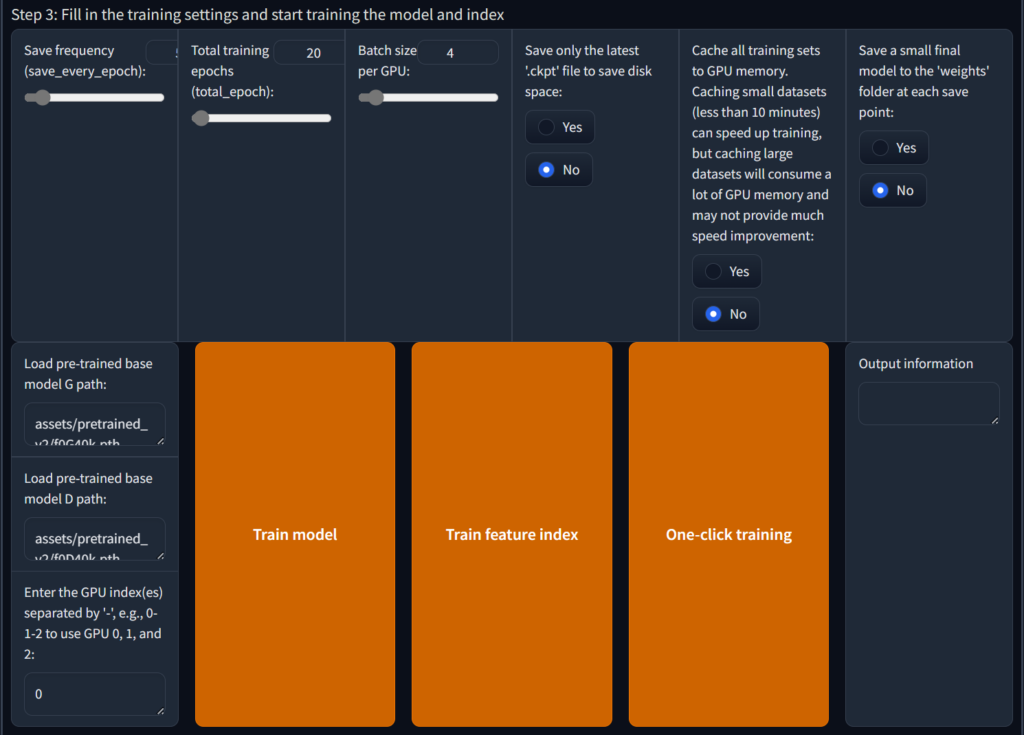
第一项 保存频率 可以保持默认,这样即使电脑断电重启后也可以接着继续训练,当然你有信心也可以直接拉满 50轮保存一次
total_epoch可以保持默认,一般默认就足以克隆音色了,但如果你的音色比较特殊(比如夹子音) 可以拉到200,但训练时间也会随之增加,Batch_size理论上来说越高训练越快,同时也越占现存,如果GPU性能差但显存大拉高后模型质量会随之下降
后面的选项建议保持不动,如果你的硬盘空间不足可以勾选仅保存最新ckpt
然后点击 一键训练 训练开始,建议关闭其他所有网页和后台程序,仅保留当前页面和后端,不要关闭网页,等待训练完成你将会在 安装目录/\assets/\weights 下找到 训练名.pth 这是你的模型文件 然后在 安装目录/\logs/\训练名 找到added_训练名xxx.index 这是你的索引文件,如果你需要分享你的模型请分享这两个文件,而不是只分享模型文件
结束
接下来,请享受您训练的模型,如果您愿意的话,还请将模型分享出来给更多人使用,建议上传到 Hugging Face