
前言
这期文章,由我来向大家介绍我我们的新朋友 GPT-SoVITS ,它的作者就是 Retrieval-based-Voice-Conversion 的主要开发者之一!RVC-Boss
这两个项目的核心都使用了 VITS 以至于能实现如此惊人的效果和快速,但是 GPT-SoVITS 和 Retrieval-based-Voice-Conversion 虽然有着千丝万缕的关系但是它们的功能却有很大的差别,Retrieval-based-Voice-Conversion 属于变声器,并且能够实时推理,而 GPT-SoVITS 目前为止还在TTS范畴,尽管开发者提到了后期会推出变声功能,不过可以让我们期待变声功能能为我们带来怎样惊艳的效果,该说的都说了,那么接下来让我们开始我们的教程
开始
项目的 readme 写的很详细,详细介绍了如何再您的计算机上安装部署,如果您使用Windows操作系统可以 下载整合包 当然,在这里我们也详细介绍整合包的使用
在您下载整合包后,您应该得到如下图的文件,大小在4gib多


接下来,使用您喜欢的解压软件解压这个整合包,我推荐使用7zip,我当前下载的使beta0217版本,那么打开后在压缩包更目录应该看到如下文件夹
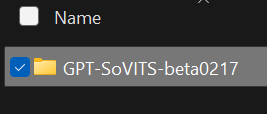
右键它,复制,然后粘贴到一个合适的位置,不要有空格或者特殊字符(比如中文),像是我,就把它解压到了 D:\
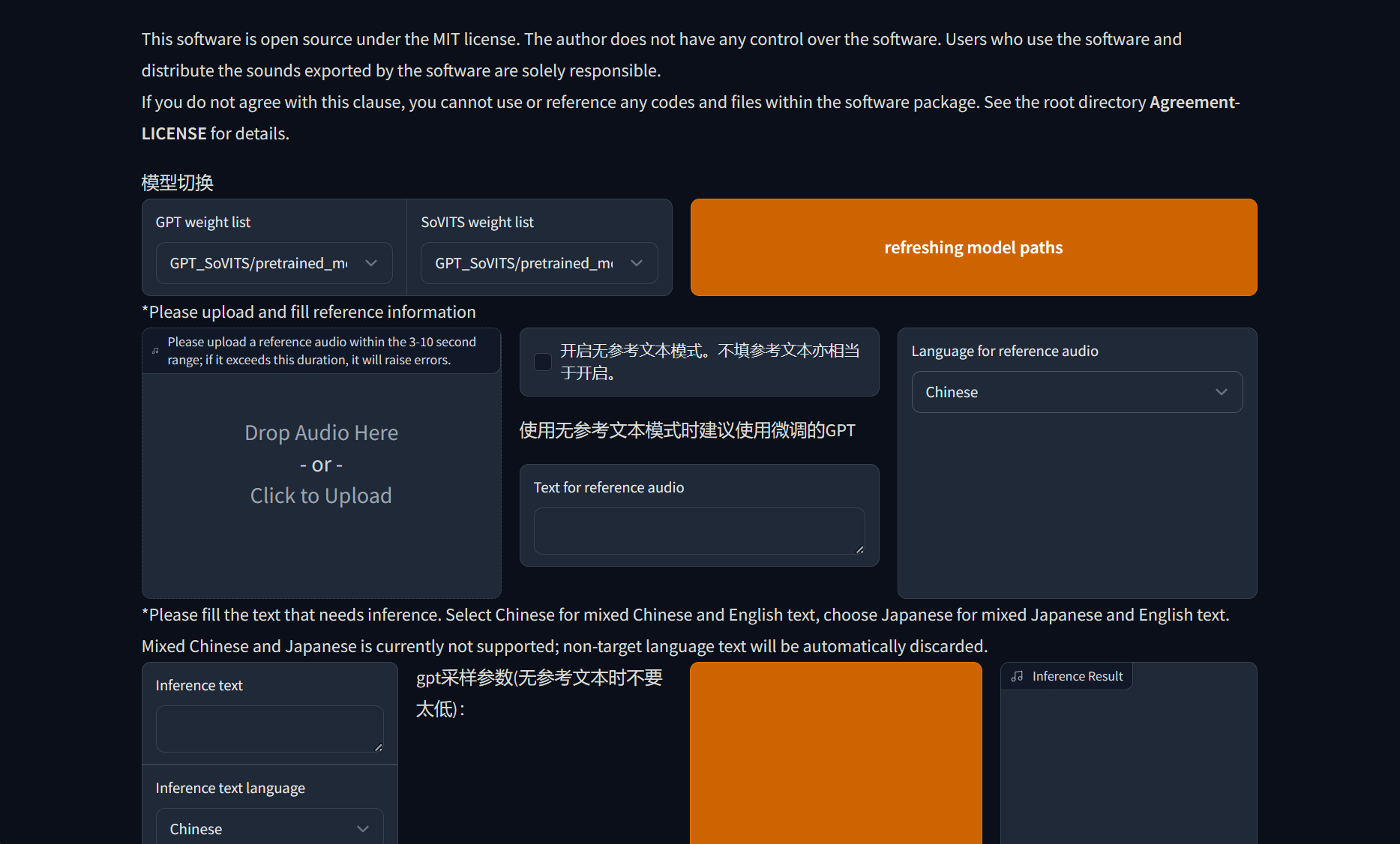
然后打开解压过后的 GPT-SoVITS-beta0217 文件夹,运行go-webui.bat(如果有网络请求窗口请点击允许),然后程序就会自动启动您的浏览器并打开如下界面
第一个区块是UVR人声分离,但我不建议使用自带的,请前往 The Ultimate Vocal Remover Application 下载,阅读 往期文章 查看推荐的模型
然后,进行语音切分,如下图
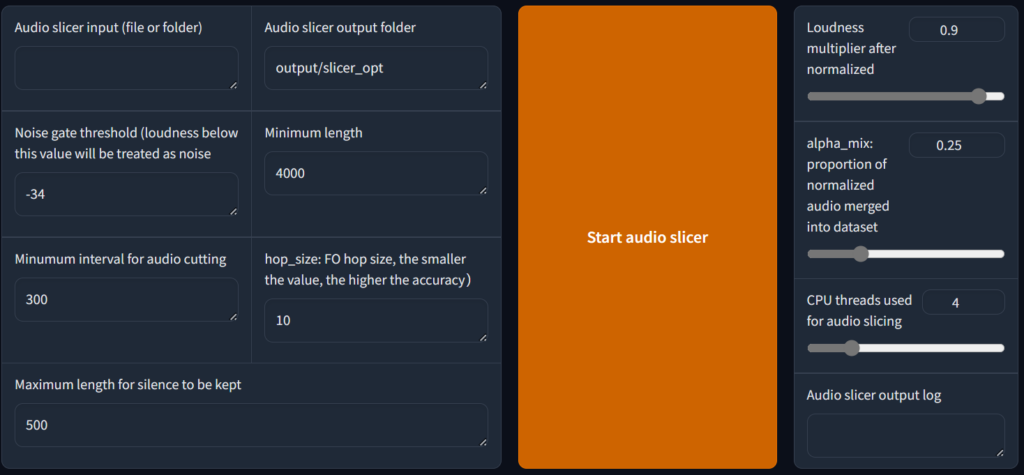
在 音频自动切分输入路径 里输入您的数据文件,支持单文件或者一个文件夹,别的无需修改,直接点击开始,然后会在终端中输出切分后的数据的路径,如下图

其中 “output\slicer_opt” 就是切分后输出的路径,然后在ASR模块输入 程序安装路径\output\slicer_opt,比如我的就是C:\GPT-SoVITS-beta0217\output\slicer_opt,然后选择语言和模型,然后点击开始
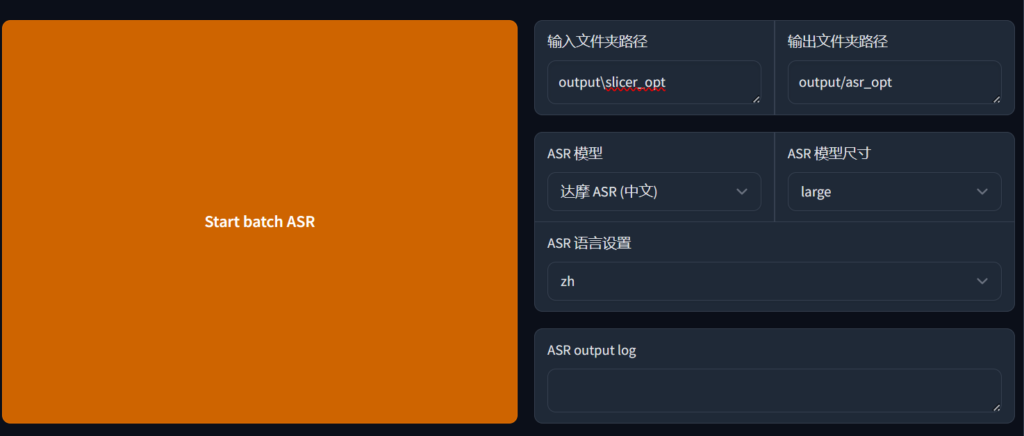
如果您是首次使用,会自动下载模型文件,请保持稳定快速的网络连接并耐心等待
下载完成后会开始处理

然后输出文件路径

复制它,然后输入到打标模块,然后点击启用

此时程序会自带打开打标页面
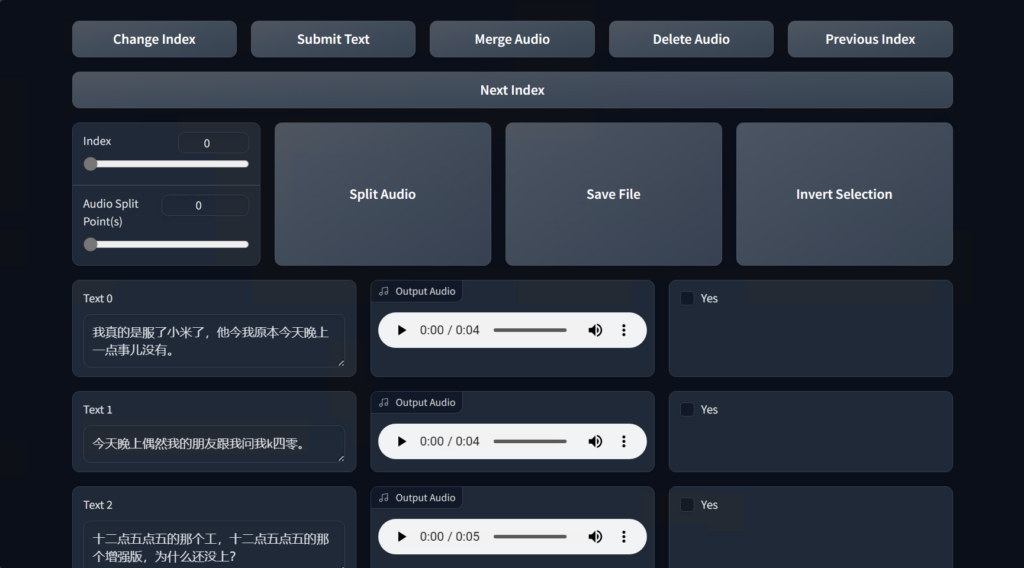
一般没什么需要修改的,得益于达摩ASR的准确识别,你只需要挑选出质量差的标注并删除即可,点击Next Index翻页,完成修改后点击Save File
然后点击 1-GPT-SOVITS-TTS 选项卡
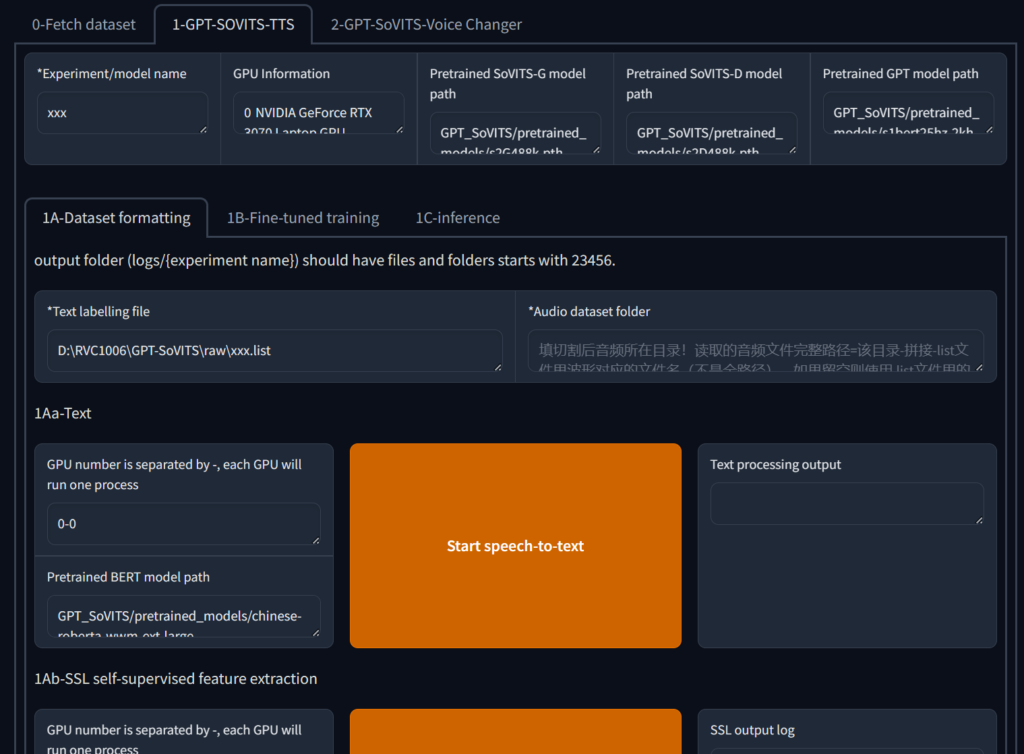
在 实验/模型名 输入一个名字,一般输入目标的名字,然后在 文本标注文件 输入之前的asr文件路径,然后在 训练集音频文件目录 输入之前的切分后文件路径,然后点击 开始文本获取
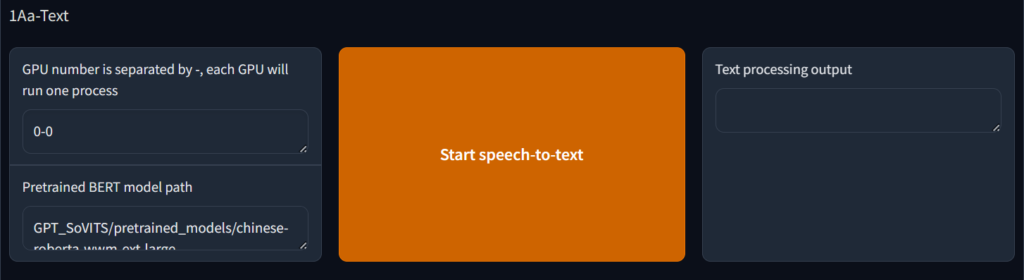
然后耐心等待 直到输出 文本进程结束
然后点击 开启SSL获取

等待执行完成后
然后点击开始语义token提取

在 实验/模型名 输入一个名字,一般输入目标的名字,然后在 文本标注文件 输入之前的asr文件路径,然后在 训练集音频文件目录 输入之前的切分后文件路径,然后滑动到页面底部点击一键三连

等输出 一键三连进程结束 后切换到 1B-微调训练
保持默认直接点击开始,如果你有特殊需求也可以调整,一般默认参数足够了
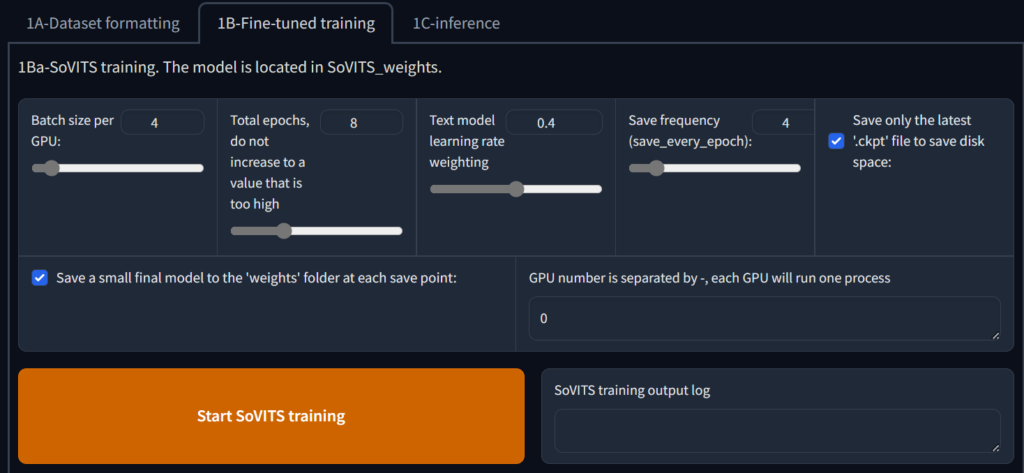
时间比较久,请耐心等待,此时可以起身出去冲一杯咖啡,舒展下身体
完成后,会在log里输出 SoVITS训练完成
然后点击 开始GPT训练
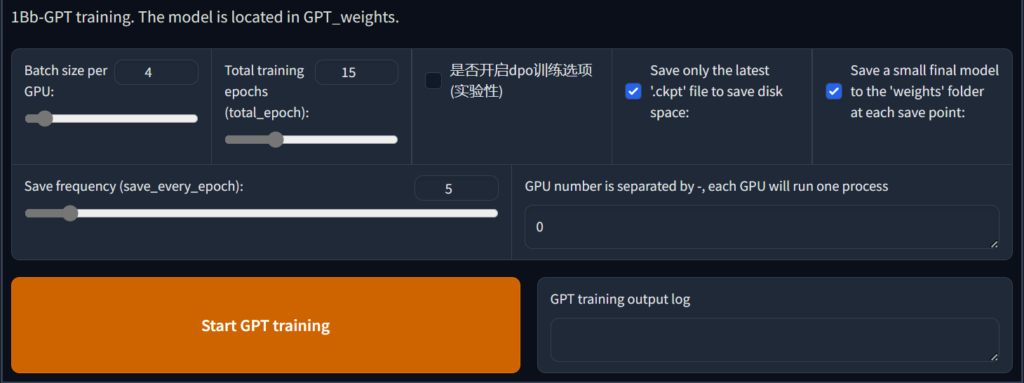
等待输出 GPT训练完成 就可以前往 1C-推理 了
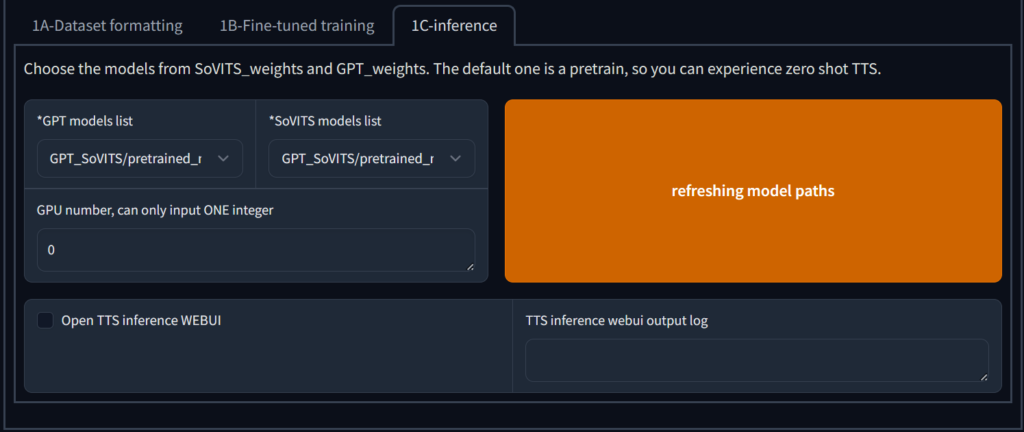
先点击 刷新 然后选择 模型,一般是 你刚刚填写的实验名-eXX.ckpt 两个模型都要选,建议选数字最大的,然后勾选 开启TTS推理WebUi ,程序会启动推理UI并在浏览器打开界面
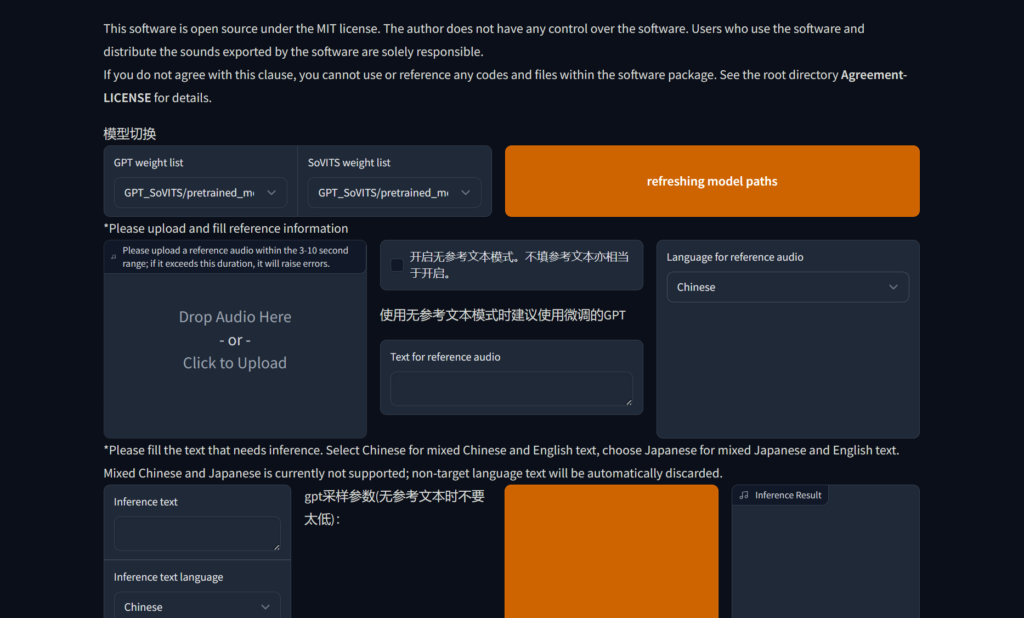
此时就可以推理了,我建议打开打标页面选择一条音频作为参考音频,然后输入参考文本
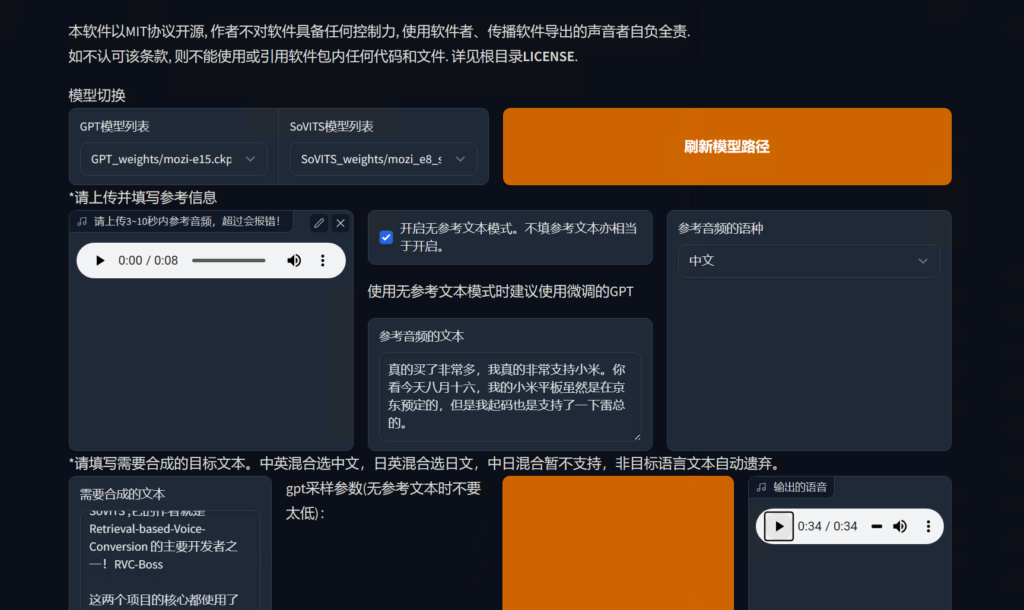
然后输入要合成的文本然后点击合成语音就开始合成了,单语言输出的效果还是非常不错的,多语言混合也将就听得过去
最后,给大家带来效果试听
效果试听
参考音频
输出音频
发表回复